
<사진 속에 들어가 다른 곳을 볼 수 있을까?>
볼 수 있을까?>
- 3차원 영상 재구성

'신념과 신뢰', 윌리엄 C. 비얼 - 1958 퓰리처상 수상작
인생의 모든 순간은 누구에게나 단 한 번만 스쳐갑니다. 좋은 순간을 오래 지속하고 싶은 것은 모든 사람의 바람이겠지만, 그런 일은 일어나지 않습니다. 그래서 사람들은 그 시간의 언저리라도 되돌리고자 다양한 방식으로 순간을 기록합니다. 글, 그림, 녹음기, 사진기, 비디오 카메라 등 정말 다양한 방식이 있지만, 그 모든 것들의 공통점은 그 순간에 기록자가 기록한 '일부'만 기록할 수 있다는 점입니다. 예컨대, 아무리 사방에 카메라를 놓고 공간과 움직임을 그대로 캡쳐하는 Volumetric Capture라 해도 그 때의 기록자가 아예 기록해 놓지 않은 장면을 복구할 수는 없습니다.
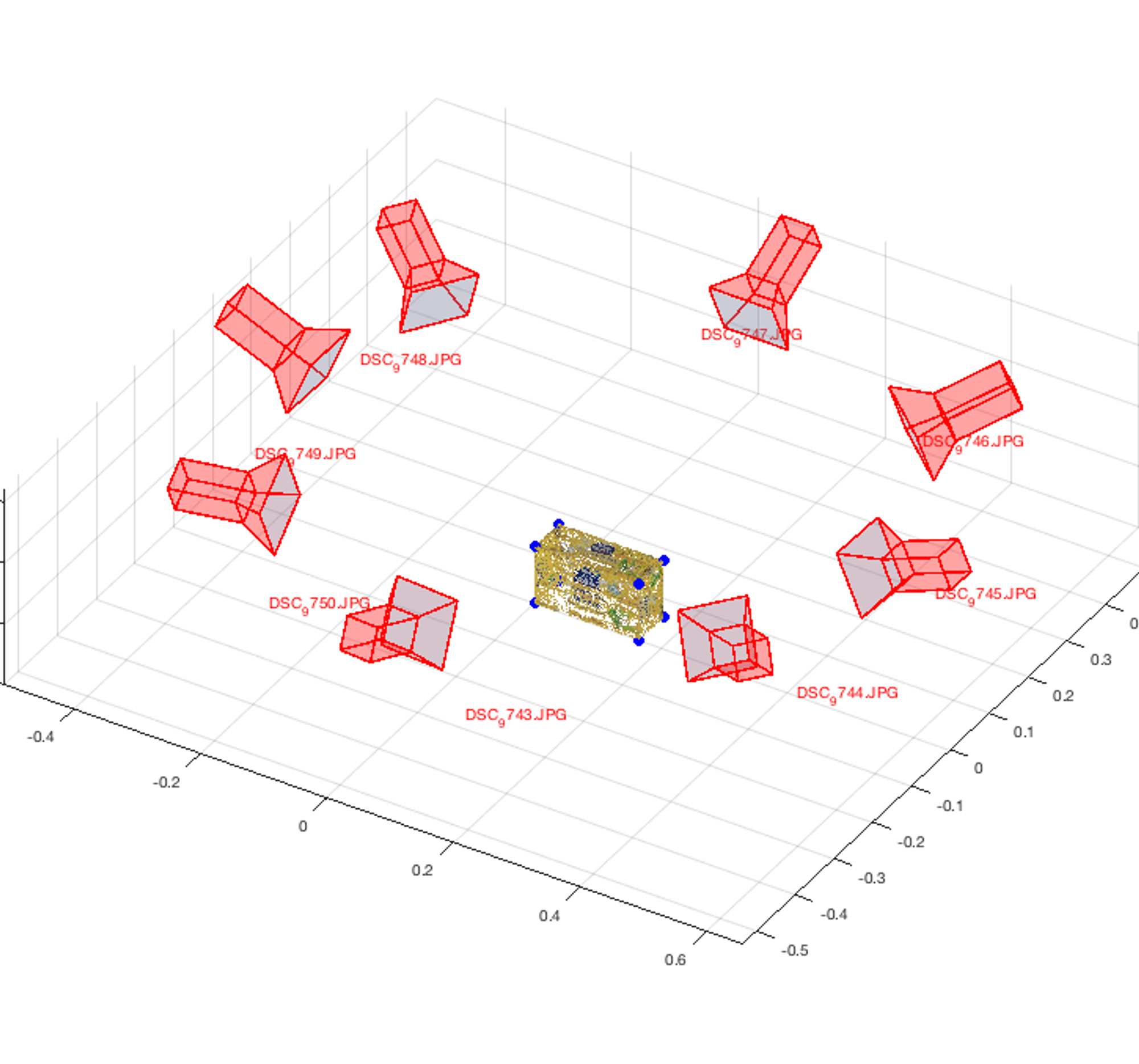
3D Model Constructed from 8 Images from Different Camera Poses(https://www.sciencedirect.com/topics/engineering/stereovision)
그러나 그 모습을 포착해 놓은 다른 사람이 있다면 어떻게 될까요? 어쩌면 각 사진에 담긴 정보로부터 '전체'를 복원할 수 있지 않을까요? 한 사람의 기록자가 놓친 부분을 다른 사람의 정보로 보완하는 방식을 통해서, 우리는 대상을 과거에 기록해 놓지 않은 ‘새로운’ 시점으로 볼 수 있습니다. 예를 들어, 대상의 a와 b부분을 담은 이미지, b와 c 부분을 담은 이미지를 적절히 잘 처리하면 대상의 a와c 부분을 함께 바라보는 ‘새로운’ 시점의 이미지를 얻을 수 있을 것입니다.

Sameer Agarwal et al., “Building Rome in a Day”
여기에 보이는 이 콜로세움은 어떻게 만들어 졌을까요? 언뜻 보면 콜로세움 앞에 LiDAR 스캐너를 놓고 캡쳐한 포인트 클라우드처럼 보이지만, 이 콜로세움은 특정 각도에서 새롭게 포착한 것이 아닙니다. 이것은 여러 사람들이 각자의 시점으로 포착한 이미지에서 공간 정보를 추출하여 콜로세움을 입체적으로 세운, 3D 모델의 일면입니다.

이 프로젝트에는 사진 웹사이트에 전부터 공유되어 있던 무려 2107장의, 서로 다른 시점에서 콜로세움을 찍은 사진이 사용되었습니다. 이미지의 아래쪽에 보이는 사각뿔이 각 사진을 찍은 사람들의 시점으로 계산된 것이며, 각 사진에서 공통적으로 나타나는 특징점과 서로 다른 촬영 각도를 복합적으로 고려하여 공간정보를 지닌 하나의 완성된 3D모델을 만들었습니다. 전체 과정은 총 21시간이며, 하루가 채 걸리지 않았다고 합니다. 이제 우리는 이 3D 콜로세움 주변의 어느 ‘새로운 위치’에 사각뿔(촬영각도)을 놓는다 하더라도 그 각도에서의 모습을 포착할 수 있게 되었습니다.
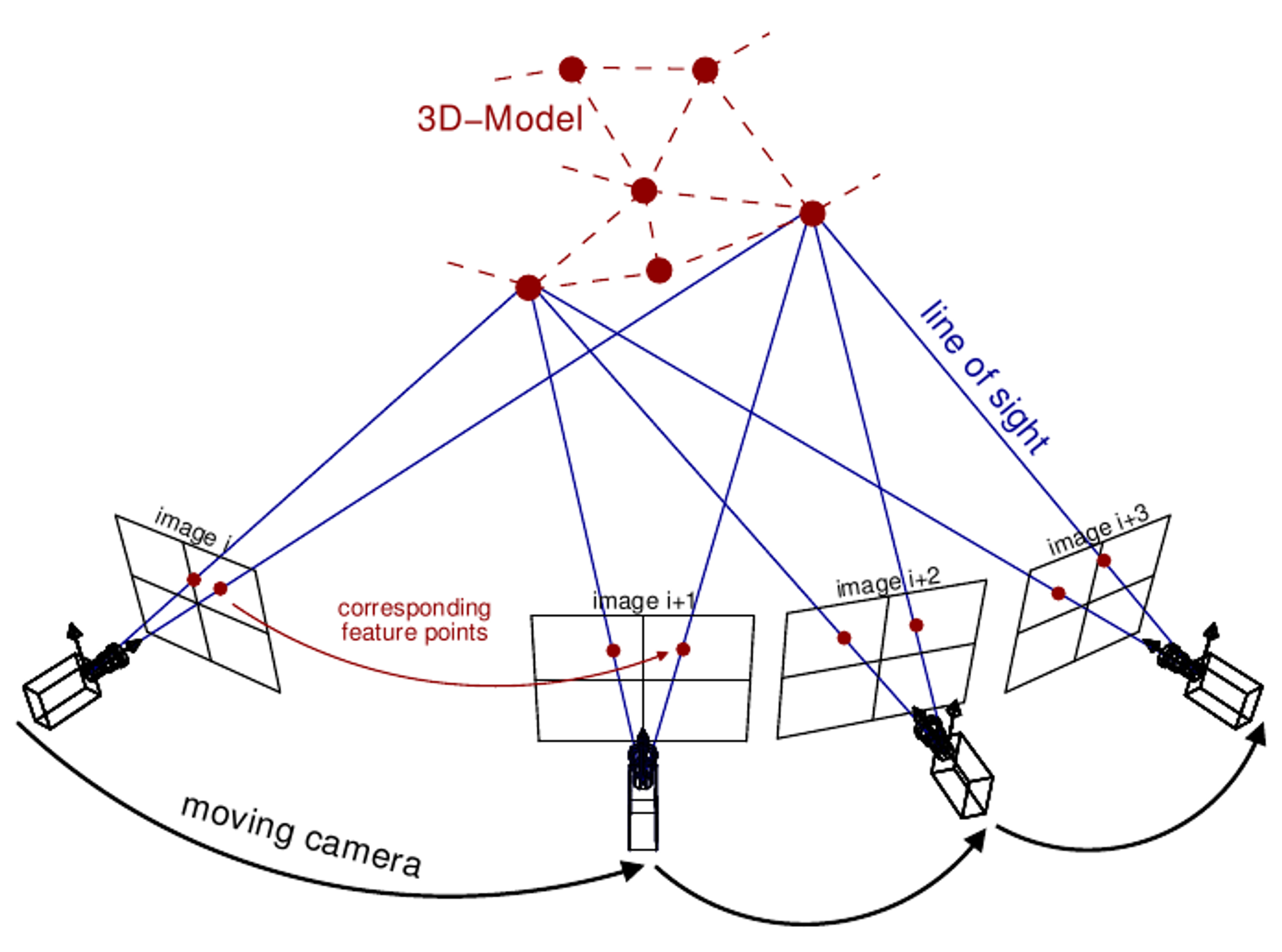
Structure from Motion (SfM) photogrammetric principle. Source: Theia-sfm.org (2016).
이처럼 하나의 대상을 서로 다른 시점에서 포착한 사진은 우리에게 '공간정보'를 줍니다. 그리고 이러한 공간정보가 충분히 모이면 우리는 평면의 사진으로부터 3D 모델을 만들 수 있습니다. 우리는
이와 같은 연구분야를 ‘Structure from Motion(SfM)’이라고 부릅니다. 이러한 2D-to-3D 변환에는 다양한 방법과 과정들이 있지만, 간단하게 요약하면 다음과 같습니다.
1.
두 장의 사진에서 공통적으로 나타난 특징점(위 사진의 빨간 점)을 여러개 찾고, 각각의 사진에서 특징점들의 위치와 그 사이의 거리를 측정합니다.
2.
측정된 위치는 각 사진마다 다르겠지만, 이는 원래 동일한 대상을 찍은 것이므로 그 차이를 통해 반대로 각각의 카메라 위치와 각도를 알 수 있습니다.
(이 과정이 끝나면 우리는 대상에 대한 듬성듬성한 특징점들로 이루어진 point cloud를 얻을 수 있습니다. )
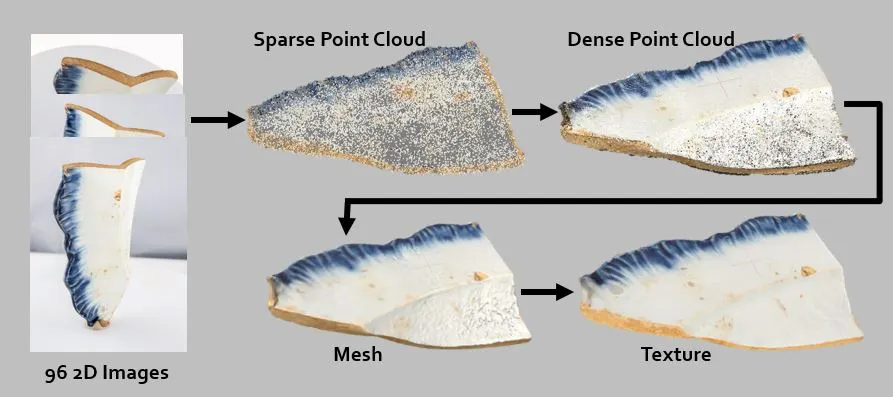
3.
각 사진 속의 정보를 기반으로 위 과정에서 얻은 듬성듬성한 point cloud를 빽빽하게 매웁니다.
4.
어느 정도 형체를 갖춘 point cloud를 좌표 공간 속에 배치하고, 메쉬 및 텍스쳐 처리를 합니다.
이렇게 우리는 여러 장의 2D사진으로부터 3D모델을 만들었고, 이제 이 모델을 통해 과거에는 보지 못했던 시점으로 대상을 또 다시 경험할 수 있게 되었습니다.
그런데 혹시, 단 한 장의 사진 만으로도 공간 정보를 얻어 새로운 시점으로 대상을 볼 수 있는 방법은 없을까요? 물론 있습니다. 이 때에는 다른 시점의 사진 대신 인간의 직관 혹은 상식이 관여하는데, 가장 가장 간단한 예를 하나 보겠습니다.

여기에 ‘Metaverse’라는 단어가 가장 처음 사용된 Neal Stephenson의 소설 ‘Snow Crash(1992)’ 책이 있습니다. 아마 다들 한 번 쯤 읽어보셨을 겁니다. 표지의 정면 이미지를 사용하고 싶은데, 찍어놓은 사진이 이렇게 비스듬한 시점의 사진밖에 없을 때, 어떻게 하면 좋을까요?
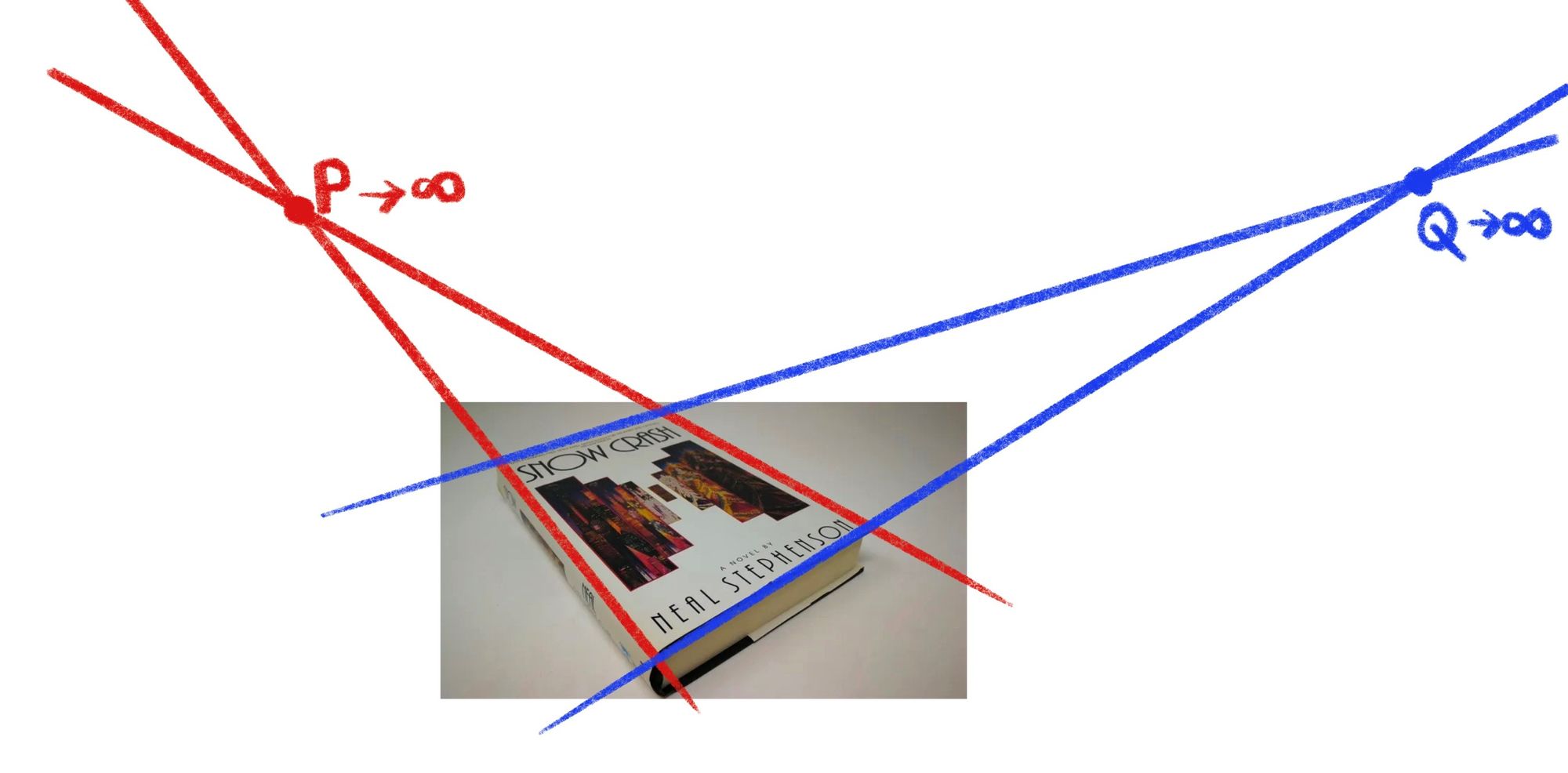
물론 여기에도 매우 여러가지 방법이 적용될 수 있겠지만, 위와 이미지와 같은 방법을 적용해볼 수 있습니다. 이 때에는 다른 시점의 사진 대신, 책의 모서리가 각각 평행하다는 우리의 상식을 이용합니다. 우선 사진에서 책의 모서리를 따라 선을 그립니다. 그리고 마주 보는 두 선이 평행하여 만나는 지점이 영원히 생기지 않도록 이미지를 변환하면 정면에서 보는 책의 표지를 얻을 수 있을 것입니다. 물론 전체적인 과정에서는 모서리를 정확하게 알아내는 과정, 이후 조정 과정 등 그 전후로도 많은 절차들이 있지만 기본적인 아이디어는 이러합니다. 이 경우에는 책의 뒷면을 전혀 알 수는 없겠지만, 액자처럼 한 면의 이미지 만을 여러 각도에서 볼 수 있도록 하거나 여러 책들의 사진을 기반으로 뒷면을 추측하여 생성하여 활용할 수 있을 것입니다.

Courtesy Vancouver Mural Festival, (https://vancouver.citynews.ca/2021/02/14/vancouver-art-augmented-reality/)
이렇게 3차원 영상 재구성을 통해 공간정보가 추가된 이미지는 특히 공간형 웹에 기반한 메타버스에서 활용도가 굉장히 높습니다. 네트워크 구성원들의 기록물을 모아 하나의 완전한 3D모델을 만들면, 직접 사진을 찍은 사람은 물론이고 그것을 경험하지 못했던 사람들까지 함께 그 경험을 공유할 수 있습니다.
특히, 이 때에는 기존의 사진 혹은 영상 기록물을 공유하는 것과는 다르게 ‘새로운’ 시점에서 대상을 처음 혹은 다시 보는 것이 가능해집니다. 따라서 시간의 흐름에 따라 같은 대상이 전혀 다른 경험을 선사할 수 있습니다. 네트워크가 확장될수록 축적되는 데이터는 많아지고, 우리가 접할 수 있는 경험은 더욱 다채로워질 것입니다. 공유된 경험은 3차원 이미지 처리를 통해 공간형 웹에서 하나의 완전한 대상으로 통합되고, 그것은 새로운 경험의 가능성을 열어줍니다.
(작성자: 김보령)